13 avril 2022 Glossaire informatique de Libelle, partie 7 : Quelle est la différence entre RPO et RTO ?
Libelle BusinessShadow®Haute disponibilité
Avec notre solution Libelle BusinessShadow® pour la reprise après sinistre et la haute disponibilité, vous pouvez mettre en miroir des bases de données et d’autres systèmes d’application avec un décalage dans le temps. Votre entreprise est ainsi protégée non seulement contre les conséquences des erreurs matérielles et applicatives, mais aussi contre les conséquences des dommages élémentaires, du sabotage ou de la perte de données due à une erreur humaine.
Notre entonnoir temporel breveté et dynamiquement ajustable stocke temporairement les journaux des modifications avant qu’ils ne soient mis en miroir sur le système de défaillance. La commutation sur le système de miroir en cas de panne ou même de maintenance peut ainsi être effectuée de manière impressionnante, rapidement et en toute simplicité.
Une base de données productive mise en miroir en 4 heures - grâce à Libelle DBShadow, un groupe de commerce international a pu relever ce défi.
Libelle BusinessShadow® crée automatiquement le système de veille. Les séquences de passage en mode d’urgence ainsi que le retour en mode normal peuvent être lancées automatiquement ou par simple pression sur un bouton. L’utilisation de la solution est simple et rapide.
Notre logiciel protège contre les conséquences des influences physiques et des erreurs logiques. Ainsi, une disponiblité globale élevée de votre système est assurée.
En tant que solution unique, Libelle BusinessShadow® peut être intégrée à SAP ainsi qu’à d’autres systèmes d’application. Même dans des environnements applicatifs complexes et indépendants, notre solution reproduit systématiquement les applications, les bases de données et les systèmes de fichiers, indépendamment de la distance.
Après la copie initiale, Libelle BusinessShadow® ne fait que refléter les logs des modifications du système de production. Ceux-ci atteignent l’entonnoir temporel en premier. Ainsi, vous pouvez fournir un système de secours opérationnel en quelques minutes.
La création du miroir de la base de données, l’envoi de l’ArchiveFile et la récupération décalée dans le temps sont effectués automatiquement par Libelle BusinessShadow®. De même, le système productif, le système de secours ainsi que tous les processus sont surveillés en permanence. En cas d’erreur, vous serez immédiatement averti par une alarme du type notification. Ceci va vous permettre de consacrer plus de temps à d’autres tâches.
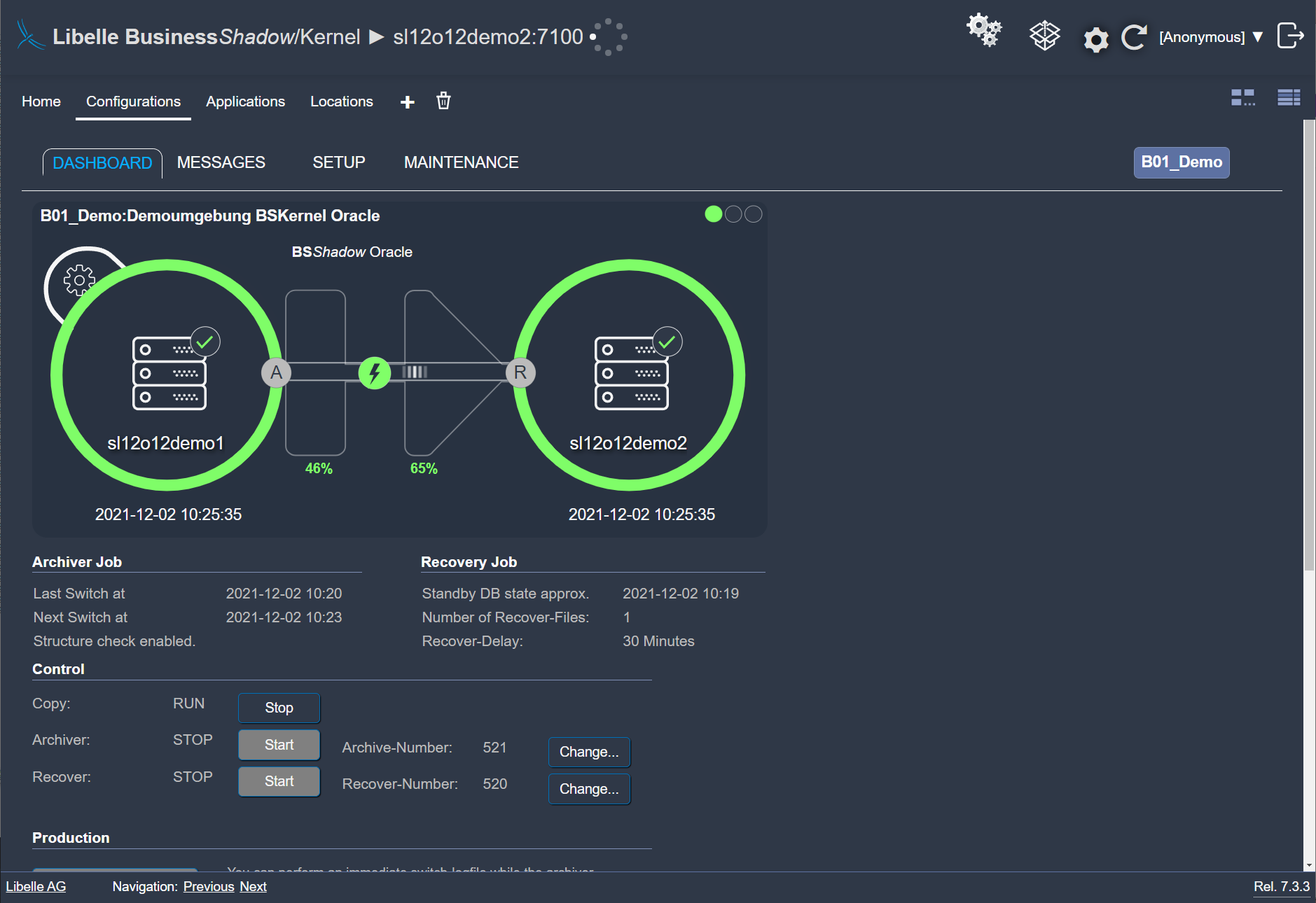
Dans cette phase, Libelle BusinessShadow® copie automatiquement toutes les données du système de production initial vers le système de secours. Nous activons la haute disponibilité et la reprise après sinistre rapidement, en toute sécurité et facilement grâce à notre entonnoir temporel breveté. Grâce à notre archiveur, seules les modifications apportées au système de production par rapport à la copie initiale sont interrogées et introduites dans l’entonnoir temporel.
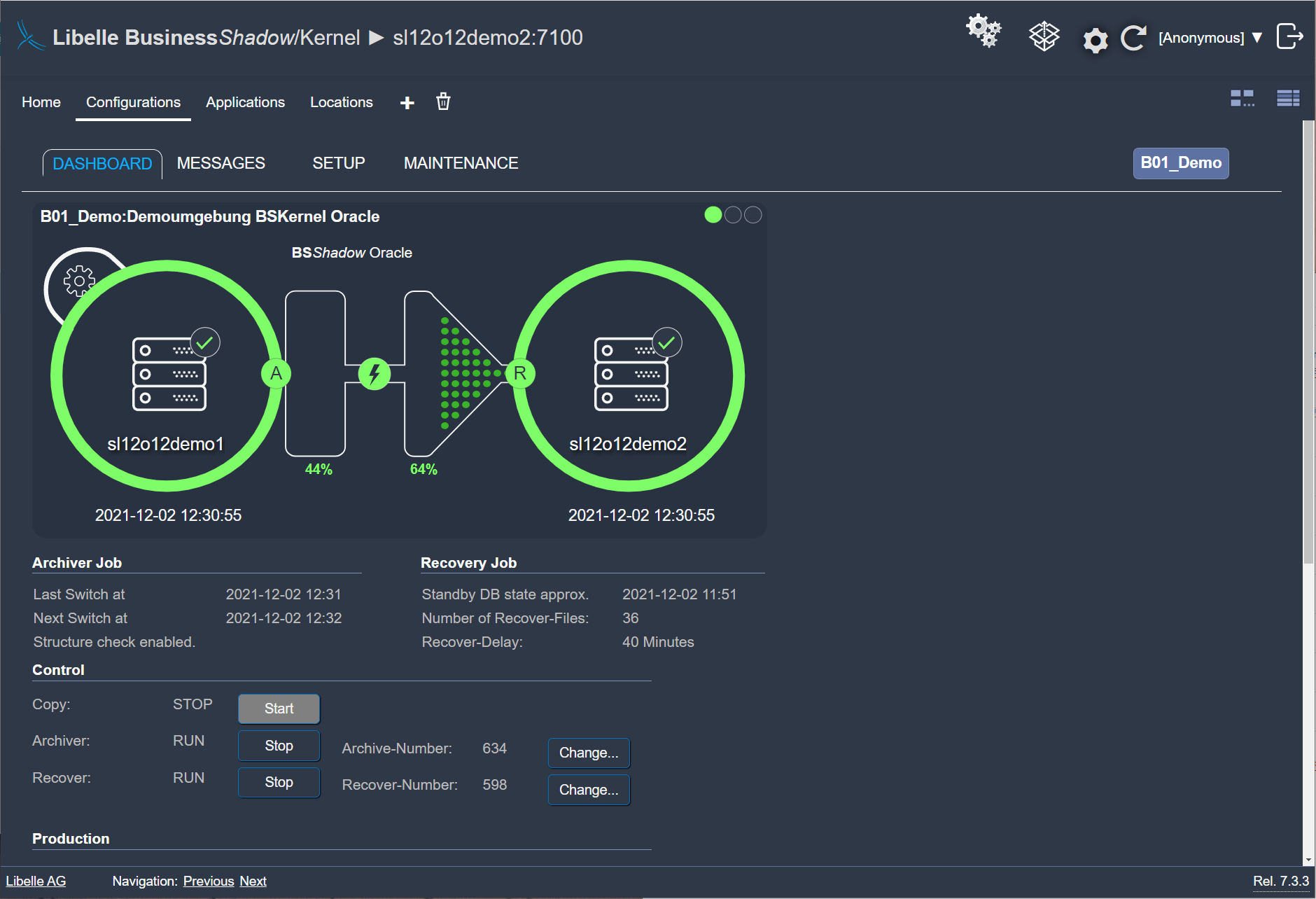
With our high availability and disaster recovery software and its unique time funnel, you have a time safeguard. Before new data is transferred to the standby-system, it is first held in the time funnel. You can determine the duration individually. In the event of errors on the production system, the data is not immediately transferred to the standby system, giving you the chance to activate this failover system at a desired time within minutes. Your backup operating system is available, and you can continue to work without interruption.
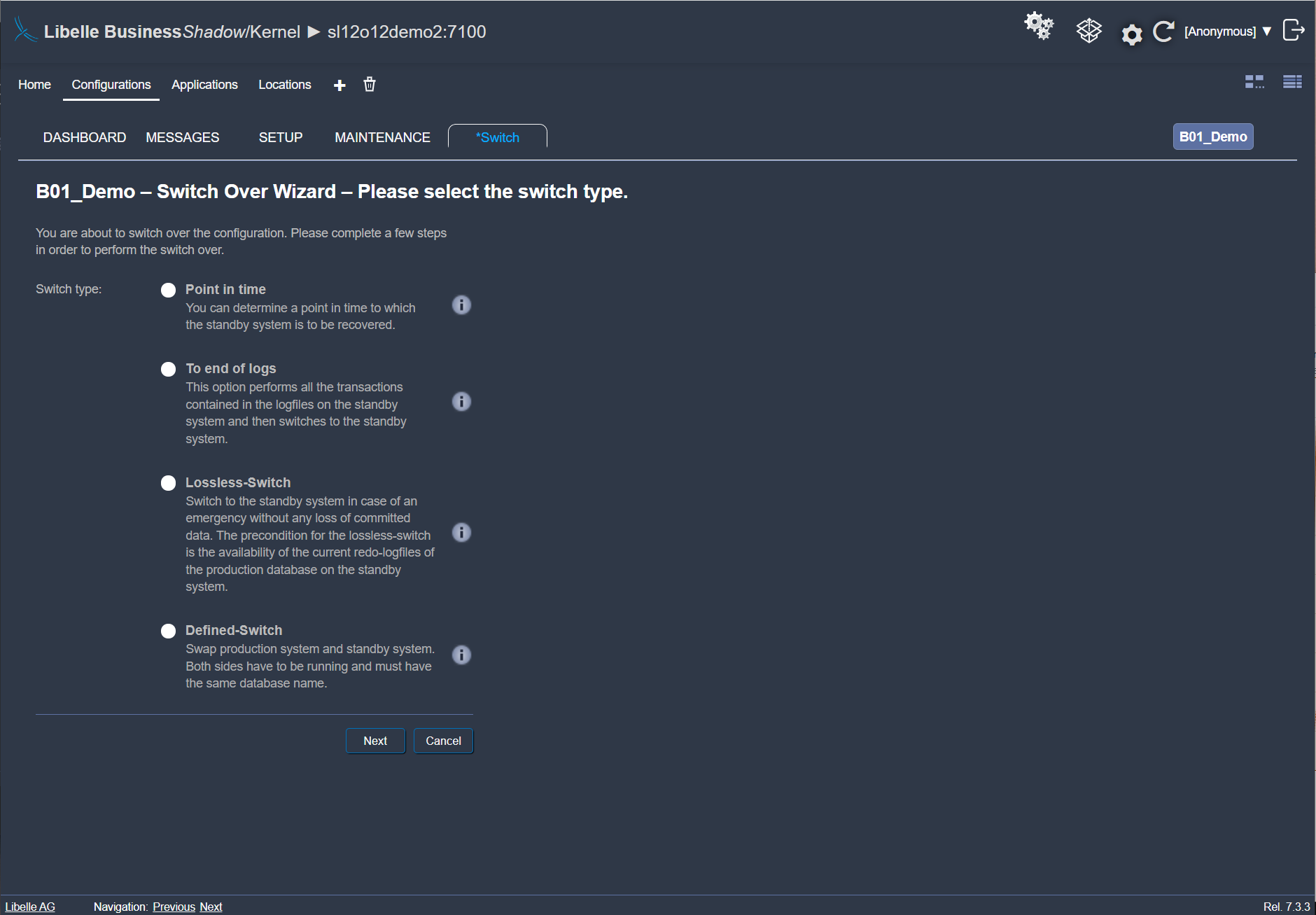
Lorsqu’une erreur s’est produite sur le système de production – par un logiciel, un utilisateur ou un job batch – le log modifié atterrit dans l’entonnoir temporel. Vous pouvez désormais passer au système de veille, manuellement ou automatiquement. Avec Libelle BusinessShadow®, vous disposez en quelques minutes un système possédant toutes les données jusqu’à peu de temps avant que l’erreur ne se produise. Votre entreprise peut désormais continuer à travailler rapidement et sans problème sur le système de secours.

Pendant que vos opérations commerciales se poursuivent normalement sur le système de secours, votre équipe informatique peut corriger l’erreur sur le système de production réel en quelques minutes. Ensuite, vous pouvez transférer automatiquement les données actuelles et cohérentes du système de secours vers le système de production et votre concept de reprise après sinistre et de disponibilité redémarre.
