Libelle IT Glossary Part 9: What does the term "Mean Time Between Failures" mean?
The reliability of an IT and software product is a property that has always been the focus of development. Hardware but also software components should completely fulfill their assigned function within a certain time frame. In general, this is referred to as the operating time of a component between failures. The technical term for this is "Mean Time Between Failures" (MTBF).
Definition of Mean Time Between Failures (MTBF)
Mean Time Between Failures is thus a unit of measurement for the reliability of software and system components. It is not an absolute value, but an average value. This means that the MTBF can be used in order to determine a central tendency which describes the reliability of the data set of a particular component (see figure). (Source)
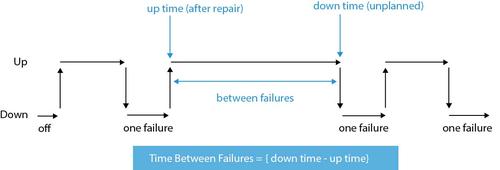
The Mean Time Between Failures is estimated to be one thousand or ten thousand hours for most components until a failure of the respective hardware or software occurs. The predefined MTBF thus often serves as a target or basis for new products in development. Intensive "stress tests" of existing products are important in order to continuously improve the Mean Time Between Failures.
But what are the concrete examples of Mean Time Between Failures?
Examples of the Mean Time Between Failures
In the hardware sector, a common example is the runtime of a product. Specifically: a hard disk, for example, has an MTBF of around 300,000 hours. The Mean Time Between Failures thus also serves as an indicator for customers when purchasing a product. Many manufacturers also advertise the high MTBF of their products. This is aimed in particular at the current megatrend of sustainability and the longevity of products, which is becoming increasingly important in today's consumer society. (Source)
Within the software sector, the focus of the Mean Time Between Failures lies on the probability of an error-free software application. The framework for this is a specified time duration and the environmental conditions. Since software applications are not of a material nature, they also do not succumb to a wear and tear mechanisms, as it is often the case with hardware components. Thus the error rate is independent of factors such as age or frequency of use.
The three general types of error within software are:
- Faulty requirement: any error within a software requirement that specifies the environmental conditions in which the software shall be used.
- Design errors: incorrect design with respect to the specified requirement
- Program errors: Errors in programming with respect to conformance with the software design (Source).
Nevertheless, software is not independent of hardware, as it is usually implemented on hardware components, thus creating a certain dependency. Thus hardware error sources can affect the error rate of a software in a negative way.
Broken down to a technical plant of a company, the following example could clarify how the Mean Time Between Failures can be calculated within such an operation:
For example, a plant may have been in operation for 1,000 hours in one year. In the course of this year, this plant has failed eight times. Therefore , the MTBF for this unit accumulates 125 hours.In order to get an accurate measurement of MTBF, you must collect data on the actual performance of the equipment. Each plant operates under different conditions and is therefore affected by human factors, such as design, installation, maintenance, software errors, and more.
Optimization opportunities for companies
Such failures are therefore also a problem from an economic point of view, which companies have to deal with. For this reason, the Mean Time Between Failures is often used as the basis for a service or maintenance plan for the product in question. It could also be said that the MTBF serves as a general time span until the component fails. Thus, measuring MTBF is a way in order to get more information about a potential failure and mitigate the impact. Calculating the mean time between failures is one way to avoid unplanned downtime in your business. There are dozens of reasons why a plant may fail. Taking stock of the symptoms is the first step to diagnosing and fixing the problem.
Prevent the worst-case scenario with Libelle BusinessShadow®
With our Libelle BusinessShadow® solution for disaster recovery and high availability, you can mirror databases, SAP® landscapes and other application systems on a time-shift basis. Your company is therefore protected not only against the consequences of hardware and application errors, but also against the consequences of natural disasters, sabotage or data loss due to human error.
Would you like to learn more about IT terms? For example, what high availability and business continuity exactly mean? Then please feel free to visit our Libelle IT glossary or follow us on LinkedIn.
Recommended articles
All blog articles